Executive summary (for busy leaders)
Using our proprietary data from LLMtel.com, we ran a 1,000-entity benchmark across 17 chatbots/LLMs where we reviewed 86,190 answers and found a hidden problem that hits brands, vendors, and even large organizations:
319 entities were “known” by at least one LLM but were never named in any answers.
We call them The Ignored.
This matters because AI visibility is now a growth lever. If your name never shows up in answers, you lose mindshare, leads, and trust no matter how good your product is.
The big takeaway is simple:
- Wikipedia (and similar sources) can help an LLM recognize you.
- But prompts and intent decide whether the LLM will say your name.
What we measured (two scores, two behaviors)
This study tracked two different things. They sound similar, but they measure different parts of the AI “attention funnel.”
A) Entity Score = “Do LLMs recognize you?”
We asked 17 different LLMs about each entity directly. If a model recognizes the entity, that counts as “known.”
Think of this as memory: Does the model have you in its head at all?
B) Questions Score = “Do you show up in answers?”
Then we asked multiple questions per entity and checked whether the entity’s name appeared in the answers.
Think of this as speech: When the model talks, does it actually say your name?
That difference memory vs. speech is where a lot of brands get stuck.
The main result: The Silent 319
Across the full set of 1,000 entities:
- 936 were known by at least one LLM
- 64 were unknown to all 17 LLMs
Now the key point: being “known” does not mean being “named.”
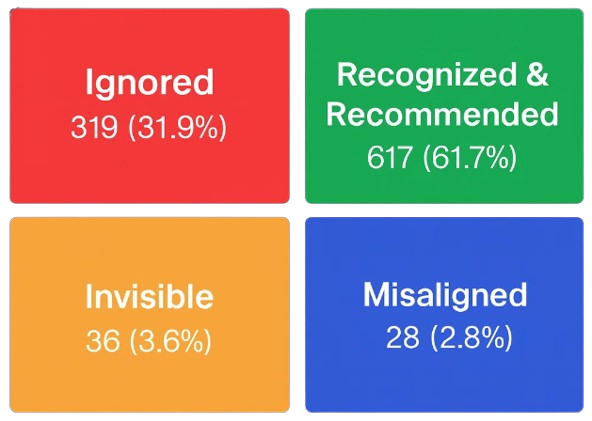
Here’s the breakdown:
| Group | Never named | Named at least once | Total |
|---|---|---|---|
| Known | 319 | 617 | 936 |
| Unknown | 36 | 28 | 64 |
| Total | 355 | 645 | 1000 |
What “The Silent 319” means
These are entities that the models recognize – but the models never say.
Put another way:
- Nearly 1 in 3 entities (31.9%) were known but never named in answers.
If you’re a leader, that’s the wake-up call: AI can know you exist and still ignore you in the moments that matter.
Recognition helps but it doesn’t guarantee visibility
One easy way to see the gap:
- Among “known” entities, about two-thirds got named at least once.
- Among “unknown” entities, less than half got named at least once.
So yes: recognition helps.
But it is not the finish line. In this study, hundreds of known entities never got into the answer layer at all.
This is why many “AI visibility” conversations go sideways. Teams celebrate that models can describe the company if asked directly, and then wonder why the company never shows up when people ask for recommendations.
The real issue: “Memory vs. speech”
Here’s the simplest way to understand what’s happening:
Entity Score is memory. Questions Score is speech.
Many organizations invest in being remembered and assume that automatically leads to being mentioned. The data says it doesn’t.
It’s like being on the guest list at the event but never getting the microphone.
Why LLMs stay silent (even when they know you)
Executives usually ask the same question here: “If the model knows us, why won’t it mention us?”
The study points to a few practical reasons.
Reason 1: LLMs default to the safest, most common answers
A lot of questions trigger generic recommendations. Models often choose:
- The most widely known brands,
- The most “standard” options,
- Or the most neutral answers.
If you aren’t a default pick, you may get skipped even if the model recognizes you.
Reason 2: The questions may not create a natural moment to mention you
Some entities never got questions that fit them well. If the prompt doesn’t open the right door, the model won’t walk through it.
Reason 3: Recommendation pressure changes behavior
When a prompt sounds like advice (“Who should I hire?” “What should I buy?”), models can become conservative. They hesitate to name specific companies unless they feel confident that:
- The company is broadly established,
- The match is obvious,
- And there’s low risk of being “wrong.”
Reason 4: Crowded categories crowd you out
In markets with strong incumbents, the same handful of names get repeated. Models behave like humans: they reach for what’s top-of-mind.
Reason 5: Naming consistency is fragile
Small differences in how your name appears online can split your “mention signal.” Things like:
- Abbreviations vs. full names
- “Inc.” vs no “Inc.”
- Parentheses
- Punctuation
- Country or regional variants
If the internet (and prompts) refer to you in many forms, models may not reliably surface the exact string you care about.
Wikipedia tie-in: Wikipedia builds memory not speech
Wikipedia is a powerful “entity anchor.” It often helps models recognize that an entity is real, distinct, and notable.
We saw that clearly in a separate slice of this project (Top 25 vs Bottom 25 scoring entities where Wikipedia pages were checked):
- Top 25: 24 out of 25 had a Wikipedia page
- Bottom 25: 4 out of 25 had a Wikipedia page
That’s an enormous gap. In plain language: Wikipedia is strongly associated with who rises to the top.
But here’s the twist:
The Silent 319 shows the next bottleneck.
Even if Wikipedia helps models recognize you, it does not guarantee the models will name you in answers.
This is the key framing:
- Wikipedia helps you get into AI memory.
- Prompts and intent decide whether you get into AI speech.
What to do about it (how to go from “known” to “named”)
If you want results, treat this like a two-stage funnel:
- Recognition: Do models know you exist?
- Inclusion: Do models choose to say your name when the user asks real questions?
Here are the practical moves.
Step 1: Track two KPIs (not one)
Most teams only measure recognition (“Can the model describe us?”). You also need inclusion (“Does the model mention us when it matters?”).
At a minimum, track:
- Recognition rate (how often models recognize you)
- Answer inclusion rate (how often you appear in answers)
Step 2: Build “prompt fit”
LLM mentions happen when the question is:
- Specific enough,
- Clear about the category,
- And confident enough to justify naming options.
So you want your public footprint to match real buyer questions, like:
- “Which tool helps with X?”
- “Who offers Y in industry Z?”
- “What platform does A for B?”
Step 3: Strengthen your identity across the web
Wikipedia can help, but it’s not the only lever.
What matters is:
- Consistent naming,
- Reputable third-party references,
- And clear “this is the same entity” signals (across listings, profiles, and sources).
Step 4: Win the sources models trust
Models learn patterns from the public web. They tend to reward:
- Credible publications,
- Reference-style content,
- Comparisons and lists,
- Citations and links.
This is less about marketing language and more about verifiable proof.
Step 5: Test like a buyer
Stop asking: “Do you know us?”
Start asking: “When do you name us?”
Run a simple monthly check:
- Pick 20 real customer questions,
- Ask multiple leading models (or use LLMtel to check),
- Count mentions,
- Look for trendlines.
The bottom line
If you’re a leader, here’s the strategic insight:
- Being known by LLMs is table stakes.
- Being named is the competitive advantage.
This study put a clear number on the problem:
319 out of 1,000 entities were silently familiar known but never spoken.
If your company is in that bucket, you won’t show up in the new decision journey where customers ask AI first.
The fix isn’t magic. It’s a shift in focus:
- From “Are we recognizable?”
- To “Are we the answer when the real questions get asked?”