What a 1,000‑entity / 17‑model benchmark teaches us about “being known” vs “being named” in LLM answers
If you’ve ever asked, “Will AI recommend our company?” you’re already asking the right question. But there’s a catch: LLMs don’t work in a single step.
In our benchmark, we saw a pattern again and again:
- Many brands are recognized by AI models… but are not mentioned when people ask questions.
That gap is where opportunity lives.
The study in one minute
We ran a structured benchmark, not a one-off demo.
- 1,000 entities
- 17 chatbots/LLMs queried per entity
- 5,070 total prompts
- 86,190 answers
This gives us something most “AI visibility” conversations don’t have: a consistent panel view across many models and many questions.
Two scores that matter (and why you need both)
Most people try to measure “AI awareness” with one metric. We used two:
1) Entity Score = “Do models recognize this entity?”
This is simple: out of 17 models, how many treated the name like a real entity.
- Example: 12/17 means 12 models recognized it.
2) Questions Score = “Does it show up in answers?”
This measures whether an entity actually appears when the models answer questions.
- Example: 47/51 means the entity showed up in 47 out of 51 answers generated from its question set.
These two scores move together but not perfectly. In the full dataset, the relationship is strong, but not absolute (correlation ≈ 0.65). Translation: recognition helps, but it doesn’t guarantee mentions.
The big pattern: “Known” is not the same as “named”
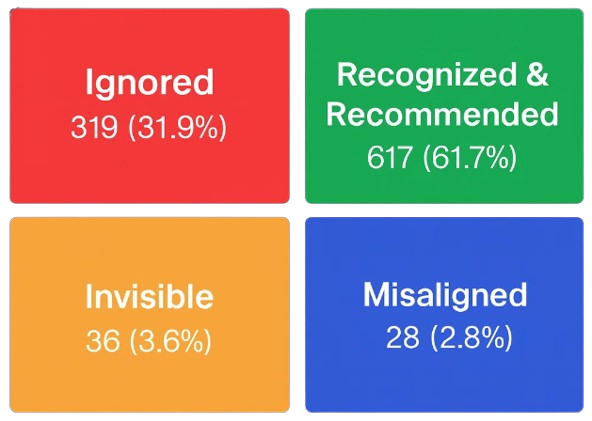
When we grouped the 1,000 entities, the split was eye-opening:
- Recognized: 617 were recognized and named (models know them and also mention them)
- Ignored: 319 were recognized but never named (models know them, but don’t bring them up)
- Misaligned: 28 were named at least once even though none of the models “recognized” them in the entity test
- Invisible: 36 were neither recognized nor named.
Two takeaways for leaders:
- There’s a large “quiet middle” of brands that are known but not activated in answers (almost 1 in 3).
- Mentions are scarce for most entities. Half of entities show up in answers only rarely, and 355 entities were never named in answers at all in this prompt set.
This is not a “good vs bad” list. It’s a map of how LLMs retrieve brand names in real conversations.
Meet the outliers: Silent Overachievers and Quiet Giants
This is where the story gets useful.
Silent Overachievers
These are entities that show up in answers more than their recognition would suggest. They tend to be:
- Tightly linked to a clear use case,
- Easy to recommend in plain language,
- A “default example” when a question implies a category.
Quiet Giants
These are entities that are widely recognized, but show up less often in answers in this prompt set. This usually happens when:
- The brand is B2B, infrastructure, or standards-focused,
- Prompts don’t strongly cue the right context,
- There are many valid alternatives so mentions spread out,
- The “best answer” is often generic guidance rather than a brand name.
The key point: Quiet doesn’t mean weak. It often means “high awareness, low activation.”
Silent Overachievers: four examples (and what they teach)
These are not rankings. They’re illustrations of a pattern: prompt intent can pull certain names into the answer.
Hertz Canada – a strong “travel intent” magnet
- Recognized by 12/17 models (about 7 in 10)
- Mentioned in 47/51 answers (about 9 in 10)
Why this happens: travel and rentals are high-frequency intents. When a question implies “rent a car,” models often reach for familiar, easy examples.
Executive lesson: If you want to be mentioned, you have to be strongly associated with a specific intent people actually ask about.
Canada Goose – clear category identity wins retrieval
- Recognized by 12/17 models (about 7 in 10)
- Mentioned in 45/51 answers (about 9 in 10)
This is what strong positioning looks like in LLM outputs: the brand becomes an obvious example when the question signals premium outerwear or cold-weather gear.
Executive lesson: Clear category identity makes retrieval easier for models.
Cacique – niche relevance can beat broad awareness
- Recognized by 1/17 models (less than 1 in 10)
- Mentioned in 63/170 answers (about 4 in 10)
This is the “specialist effect.” Even when general recognition is low, a brand can surface frequently when the questions align with a specific product or cuisine context.
Executive lesson: You don’t need universal awareness to win. You need strong relevance to a real question.
Nelson Education – authority shows up when the prompt fits
- Recognized by 4/17 models (about 2 in 10)
- Mentioned in 29/85 answers (about 3 in 10)
Education prompts tend to reward recognizable publishers and resources when users ask for practical guidance.
Executive lesson: In intent-rich categories, credibility and usefulness can drive mentions even without broad fame.
Quiet Giants: widely recognized, less frequently triggered (and why that’s normal)
These examples are “quiet” in this prompt set, but they’re clearly known.
Porter Novelli – recognized everywhere, mentioned selectively
- Recognized by 17/17 models
- Mentioned in 2/85 answers
This pattern usually shows up when the prompt set doesn’t repeatedly ask the kinds of questions that force a specific agency name – like “Which PR agency should I hire for X?”
Executive lesson: High recognition is an asset. The next step is making your brand more naturally cued by the language users ask with.
Topgolf – very well known, intent-sensitive retrieval
- Recognized by 17/17 models
- Mentioned in 8/170 answers
Topgolf tends to surface when the question clearly implies outings, venues, group entertainment, or corporate events. If the prompt mix leans toward other needs, mentions stay low.
Executive lesson: Some brands are “intent-locked.” They show up when the question hits their trigger.
Ricoh – strong recognition, fewer default mentions
- Recognized by 16/17 models
- Mentioned in 10/170 answers
Established enterprise brands often need sharper contextual cues (copiers, imaging, managed print, etc.). Without that cue, models may answer at a category level.
Executive lesson: The more “broad” your category, the more you must win specific sub-intents to increase mentions.
What leaders should do with this (a practical, positive playbook)
If you take only one thing from this: optimize for activation, not just awareness. Here’s the executive version:
1) Track two KPIs, not one
- “Are we recognized?” (Entity Score)
- “Are we named?” (Questions Score)
If your recognition is high but mentions are low, that’s not a problem it’s a roadmap.
2) Identify your “intent triggers”
Pick 5–10 question types you want to win, like:
- “Which tool is best for _?”
- “Who provides _ in _?”
- “How do I _?”
- “Compare _ vs _”
Then ask: Do we show up when those questions are asked?
3) Reduce naming friction
LLMs are sensitive to naming variance. Make your official name consistent across:
- Your website,
- Press coverage,
- Partner listings,
- Product pages,
- “About” pages and FAQs.
This helps models treat your identity as one clear entity.
4) Publish clear, factual, intent-matching content
Not fluff. Not hype. Just clean answers to real questions:
- What you do,
- Who you’re for,
- When you’re the right fit,
- How to buy/use/contact.
LLMs reward clarity because clarity is easy to learn and easy to reuse.
5) Re-measure and watch movement
The win isn’t “perfect scores.” The win is moving from:
- Recognized → named more often in the intents you care about.
The optimistic conclusion
Silent Overachievers prove something important: relevance can outperform raw fame.
Quiet Giants prove something even better: recognition is already there you can activate it.
In a world where AI answers shape perception, consideration, and purchase paths, that’s not a threat. It’s leverage.