AI has become a discovery channel. People ask chatbots who the “top vendors” are, what brands are “trusted,” and which options are “best.” If your organization doesn’t show up, you don’t just miss attention you miss consideration.
But here’s the twist from the LLMtel 1,000-entity study: a lot of organizations are already “known” by AI and still get ignored.
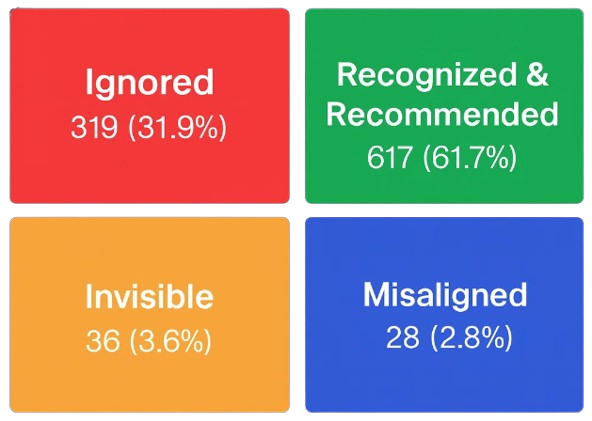
The “Ignored” bucket: known, but never mentioned
We studied 1000 entities, and each entity has two core signals:
- Entity Score: how many of the 17 chatbots/LLMs recognize the entity.
- Questions Score: how often the entity shows up in answers when each of the 17 chatbots/LLMs answers a prompt.
A painful category emerges:
- Known & Not Named (“Ignored”): the entity is recognized by at least one model, but never appears in answers.
There are 319 entities in this Ignored bucket. That’s nearly one-third of the 1,000 entities tested.
So for these 319 entities, the problem is not “AI has never heard of us.”
The problem is: AI doesn’t bring us up.
A simple test inside that bucket
To understand what separates the “more widely recognized” ignored entities from the “barely recognized” ignored entities, we pulled two groups from inside the 319:
- The Top 25 (most recognized by LLMs, based on Entity Score – how many of the 17 chatbots/LLMs know the entity – scores of 17/17, 16/17, and 15/17).
- The Bottom 25 (least recognized by LLMs, based on Entity Score – scores of 1/17, 2/17, and 3/17).
Then we asked one blunt question: Do any of the Top 25, or Bottom 25, have a Wikipedia page?
The result is hard to ignore
Even though all 50 entities are ignored in answers, Wikipedia still sharply separates the top from the bottom.
- In the Top 25 entities, 24 of 25 do have a Wikipedia page.
- In the Bottom 25 entities, only 4 of 25 do have a Wikipedia page.
That’s the story in one breath: Wikipedia presence tracks strongly with being “more known” across LLMs even when the entity is still never mentioned.
The headline numbers (kept simple)
When we turn those counts into “likelihood”:
- If an entity has a Wikipedia page, it’s about 86% likely to land in the Top 25 of this Ignored slice.
- If it does not have a Wikipedia page, it’s about 5% likely to land in the Top 25.
And the punchline statistic:
- The odds of being in the Top 25 (vs Bottom 25) are about 126× higher when a Wikipedia page exists.
Most people say, “Wikipedia matters.”
This shows how much it matters for recognition even when it doesn’t solve being ignored.
The leadership insight: Wikipedia helps “known,” not “named”
This is the part executives should care about:
1) Recognition is not recommendation
These entities are not Top 25 overall. They are Top 25 within a group that never gets mentioned. So Wikipedia is not acting like a magic “get recommended” switch.
What it does appear to do is help with something earlier in the chain:
- Step 1: Become clearly recognized as a real entity across many models.
- Step 2: Become relevant enough to be retrieved and named in answers.
Wikipedia seems to help Step 1.
Step 2 is a different fight.
Why Wikipedia is such a strong divider (in plain terms)
Think of Wikipedia as an “identity anchor” for machines:
- It standardizes the name. Fewer identity errors, less confusion.
- It’s neutral and cited. Models tend to trust sources that look factual, not promotional.
- It’s heavily connected. Wikipedia pages get referenced and copied across the web, so the “entity record” spreads.
In practical terms: Wikipedia often acts like a clean, durable reference point in the public information graph that AI learns from.
Then why are Wikipedia entities still “Ignored”?
Because being recognized and being mentioned are different behaviors.
Common reasons an entity stays unmentioned even when models “know” it:
- The question set doesn’t naturally call for it (wrong context).
- Models default to “usual suspects” in recommendations.
- The entity isn’t strongly tied to the phrases people use (“best payroll provider,” “top CRM,” etc.).
- There’s not enough third-party content that places the entity inside a clear category (comparisons, lists, analyst coverage, integration directories, procurement docs, reviews).
In one sentence:
- You can be real, documented, and known and still not be top-of-mind at the moment the model is picking names.
What a CEO should do with this (without turning it into a Wikipedia project)
First: diagnose your visibility problem
Most organizations are in one of three states:
- Unknown: models don’t reliably recognize you
- Ignored: models recognize you, but don’t mention you
- Named: you show up consistently
This article is about the Ignored bucket and what predicts stronger recognition inside it.
If you’re Unknown (recognition problem)
Wikipedia may correlate with recognition, but the practical goal is broader:
- Build a consistent, third‑party “public record”
- Make naming consistent across credible sources
- Reduce ambiguity (especially if your name is generic)
If you’re Ignored (recommendation problem)
Treat it like go‑to‑market visibility, not PR:
- Tighten category language (“we are X for Y”)
- Earn third-party mentions that connect you to that category
- Show up in comparisons, directories, and integration ecosystems
- Build “adjacency” content that makes retrieval easy (who you compete with, what you integrate with, where you fit)
And a quick ethical note
Don’t try to “force” Wikipedia. If a page is appropriate, it should be supported by independent, reliable coverage and written neutrally. If it’s not appropriate, the right move is to strengthen the underlying public record.
Bottom line
Inside the 319-entity Ignored bucket entities that never show up in answers Wikipedia still matters a lot.
- With Wikipedia, entities are much more likely to sit in the “more widely recognized” end of the Ignored group.
- Without Wikipedia, entities cluster in the “barely recognized” end.
The real strategic takeaway is not “go get a Wikipedia page.”
It’s this:
- AI visibility is a two-step game. Wikipedia helps you become “known.”
- To become “named,” you need relevance, category fit, and third-party context where the model learns what to recommend.